ANALISIS SINTACTICO
5.1 GLC.
Gramáticas Libres de Contexto (GLC), o de tipo 2: las reglas son de la forma X → α, donde X es una variable y α es una cadena que puede contener variables y constantes. Estas gramáticas producen los lenguajes Libres de Contexto (abreviado “LLC”)
- Capturan la noción de constituyente sintáctico y la noción de orden.
- Herramienta formal que puede ser vista tanto desde un punto de vista generador como estructurador.
- Propiedades computacionales interesantes: se puede reconocer en tiempo polinómico.
Una Gramática Libre de Contexto es una tupla con 4 parámetros:
- G = (V, T, P, S)
- V – conjunto de símbolos variables
- T – conjunto de símbolos terminales
- S Є V, símbolo inicial
- P – conjunto de reglas de producción: A → α, con α sucesión de símbolos de V U T, eventualmente vacía (α = ε)
Una GLC es un dispositivo generador.
Definimos el lenguaje LG generado por una gramática G del siguiente modo: G = { w / S →* w } , siendo ⇒* una “especie” de clausura transitiva de → y w una tira de terminales
5.2 Árbol de derivación.
Es una representación gráfica (en forma de árbol invertido) de un proceso de derivación en una gramática. Se define el árbol de derivación como sigue:
- la raíz del árbol será el símbolo inicial de la gramática
- los nodo interiores del árbol están etiquetados por los símbolos no terminales
- las hojas están etiquetadas por símbolos terminales
- si un nodo interior etiquetado por A, posee como hijos los nodos etiquetados por X1,X2, …Xn , entonces A→ X1,X2, …Xn es una producción de la gramática, en donde Xi , representa símbolo terminal o no terminal.
Sea la siguiente gramática:
G=( Σ={a, b}, N={S,A,B},S P ) P: S→aABAa , A→ε |aA , B→ε|bB la construcción de un árbol de derivación en el proceso de la generación de la palabra aa es el siguiente:
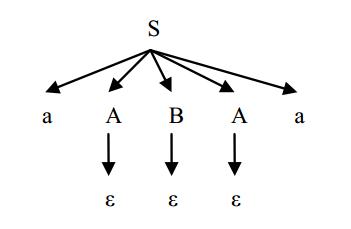
Propiedades de un árbol de derivación.
Sea G = (N, T, S, P) una gramática libre de contexto, sea A Є N una variable. Diremos que un árbol TA= (N, E) etiquetado es un árbol de derivación asociado a G si verifica las propiedades siguientes:
- La raíz del árbol es un símbolo no terminal
- Cada hoja corresponde a un símbolo terminal o λ.
- Cada nodo interior corresponde a un símbolo no terminal.
Para cada cadena del lenguaje generado por una gramática es posible construir (al menos) un árbol de derivación, en el cual cada hoja tiene como rótulo uno de los símbolos de la cadena.

Árbol de derivación.
Ejemplo:
Sea G=(N, T, S, P) una GLC con P: S→ ab|aSb
La derivación de la cadena aaabbb será: S → aSb → aaSbb → aaabbb y el árbol de derivación:

Ejercicio:

EJERCICIO:
5.3 Formas normales de Chomsky.
Una gramática formal está en Forma normal de Chomsky si todas sus reglas de producción son de alguna de las siguientes formas:
A → BC o
A → a o
donde A, B y C son símbolos no terminales (o variables) y α es un símbolo terminal.
Todo lenguaje independiente del contexto que no posee a la cadena vacía, es expresable por medio de una gramática en forma normal de Chomsky (GFNCH) y recíprocamente. Además, dada una gramática independiente del contexto, es posible algorítmicamente producir una GFNCH equivalente, es decir, que genera el mismo lenguaje.
Sea G = (∑ N, ∑T, P, $) una gramática con P ⊂ ∑N X (∑N U ∑T)* y X Є ∑N un símbolo no-terminal (o una variable). Podemos clasificar tales símbolos X en tres clases:
Variables accesibles:
- Si existe una derivación desde el símbolo inicial que contiene X, es decir, existe $ → * α Xβ donde α, β Є∑*
Variables generativas:
- Si existe una derivación desde el la variable que produce una sentencia , es decir, existe X →* ω donde ω Є *T.
Variables útiles:
- Si existe una derivación desde el símbolo inicial usando que produce una sentencia ω, es decir, existe $ →* α X β →*ω donde α, β Є ∑* y ω Є ∑*T.
5.4 Diagramas de sintaxis
Los diagramas sintácticos, de sintaxis o diagramas del ferrocarril son una forma de representar una gramática libre de contexto. Representan una alternativa gráfica para la Forma de Backus-Naur (BNF, por sus siglas en inglés) o la Forma Extendida de Backus-Naur (EBNF, por sus siglas en ingles).
Los diagramas de ferrocarril son más comprensibles para la mayoría de la gente. Alguna parte de la popularidad del formato de intercambio de datos JSON se debe a su representación en los diagramas de ferrocarril.
Un segundo método alternativo para desplegar las producciones de ciertas gramáticas de tipo 2 es el diagrama de sintaxis. Ésta es una imagen de las producciones que permite al usuario ver las sustituciones en forma dinámica, es decir, verlas como un movimiento a través del diagrama. En la figura 10.5 se ilustrará los diagramas que resultan de la traducción de conjuntos de producciones típicos, que son, por lo general, todas las producciones que aparecen en el lado derecho de algún enunciado BNF.

5.5 Eliminación de la ambigüedad
Una GLC es ambigua si existe una cadena w Є L(G) que tiene más de una derivación por la izquierda o más de una derivación por la derecha o si tiene dos o más arboles de derivación .
En casi de y que toda cadena w Є L (G) tenga un único árbol de derivación no es ambigua.
Ejemplo: La gramática S → aS| Sa | a es ambigua porque aa tiene dos derivaciones por la izquierda S Þ aS Þ aa S Þ Sa Þ aa.

Tipos de Ambigüedad
Dentro del estudio de gramáticas existen dos tipos fundamentales de ambigüedad, los cuales son:
Ambigüedad Inherente:
Las gramáticas que presentan este tipo de ambigüedad no pueden utilizarse para lenguajes de programación, ya que por más transformaciones que se realicen sobre ellas, nunca se podrá eliminar completamente la ambigüedad que presentan:
Un lenguaje L es inherentemente ambiguo si todas sus gramáticas; si existe cuando menos una gramática no ambigua para L, L no es ambiguo.
- El lenguaje de las expresiones no es Ambiguo
- Las expresiones regulares no son ambiguas
Ejemplo de un lenguaje inherentemente ambiguo:

La gramática es ambigua: hay cadenas con más de una derivación más izquierda:

5.6 Generación de matriz predictiva (cálculo first y follow)
FIRST: Sea G := (V; ∑; Q0; P) una gramática libre de contexto. Para cada forma sentencial α Є (V U ∑)* y para cada k Є N definiremos la función.
En otras palabras, el operador F IRST k asocia a cada forma sentencial los primeros k símbolos de cualquier forma terminal alcanzable desde α mediante derivaciones “masa la izquierda".
FOLLOW: Con las mismas notaciones anteriores, para cada forma sentencial α Є (V U ∑)* definiremos la función FOLLOWG GK (α) del modo siguiente.

De nuevo nos ocuparemos solamente de FOLLOW: = FOLLOW1. Obsérvese que FOLLOW k (α) ⊂ ∑* y que para cada x Є FOLLOW (α), Ixl ≤ k. Obsérvese que para cada variable A Є V, FOLLOW(A) son todos los símbolos terminales que pueden aparecer a la derecha de A en alguna forma sentencial de la gramática.
5.7 Tipos de analizadores sintácticos
Analizador Descendente:
Se construye el árbol de análisis sintético partiendo del símbolo inicial y aplicando las producciones mediante derivaciones por la izquierda, el símbolo a expandir es el que esta mas a la izquierda.
Analizador Ascendente:
Se construye el árbol de análisis sintético partiendo de la frase a reconocer y aplicando las producciones mediante reducciones hasta llegar al símbolo inicial de la gramática.
Se construye el árbol de análisis sintético partiendo de la frase a reconocer y aplicando las producciones mediante reducciones hasta llegar al símbolo inicial de la gramática.
Ejemplo:
G= ({+,*, ID, (,)}, {E, T, P},E, P)P={E:=E+T | T; T:=T*P | P; P:= ID | (E) }FraseID + ( ID * ID )
Ejemplo:
G= ({+,*, ID, (,)}, {E, T, P},E, P)P={E:=E+T | T; T:=T*P | P; P:= ID | (E) }FraseID + ( ID * ID )
G= ({+,*, ID, (,)}, {E, T, P},E, P)P={E:=E+T | T; T:=T*P | P; P:= ID | (E) }FraseID + ( ID * ID )
Ejemplo:
G= ({+,*, ID, (,)}, {E, T, P},E, P)P={E:=E+T | T; T:=T*P | P; P:= ID | (E) }FraseID + ( ID * ID )

5.8 Manejo de errores.
Un compilador es un sistema que en la mayoría de los casos tiene que manejar una entrada incorrecta. Sobre todo en las primeras etapas de la creación de un programa, es probable que el compilador se utiliza para efectuar las características que debería proporcionar un buen sistema de edición dirigido por la sintaxis, es decir, para determinar si las variables han sido declaradas antes de usarla, o si faltan corchetes o algo así.
Por lo tanto, el manejo de errores es parte importante de un compilador y el escritor del compilador siempre debe tener esto presente durante su diseño.
Hay que señalar que los posibles errores ya deben estar considerados al diseñar un lenguaje de programación. Por ejemplo, considerar si cada proposición del lenguaje de programación comienza con una palabra clave diferente (excepto la proposición de asignación, por supuesto). Sin embargo, es indispensable lo siguiente:
El compilador debe ser capaz de detectar errores en la entrada;
Un compilador es un sistema que en la mayoría de los casos tiene que manejar una entrada incorrecta. Sobre todo en las primeras etapas de la creación de un programa, es probable que el compilador se utiliza para efectuar las características que debería proporcionar un buen sistema de edición dirigido por la sintaxis, es decir, para determinar si las variables han sido declaradas antes de usarla, o si faltan corchetes o algo así.
Por lo tanto, el manejo de errores es parte importante de un compilador y el escritor del compilador siempre debe tener esto presente durante su diseño.
Hay que señalar que los posibles errores ya deben estar considerados al diseñar un lenguaje de programación. Por ejemplo, considerar si cada proposición del lenguaje de programación comienza con una palabra clave diferente (excepto la proposición de asignación, por supuesto). Sin embargo, es indispensable lo siguiente:
El compilador debe ser capaz de detectar errores en la entrada;
- El compilador debe recuperarse de los errores sin perder demasiada información;
- Y sobre todo, el compilador debe producir un mensaje de error que permita al programador encontrar y corregir fácilmente los elementos (sintácticamente) incorrectos de su programa.
Errores Sintácticos.
Muchos errores de naturaleza sintáctica Recuperación: Al producirse un error el compilador debe ser capaz de informar del error y seguir compilando. (Ideal).
El manejo de errores de sintaxis es el más complicado desde el punto de vista de la creación de compiladores. Nos interesa que cuando el compilador encuentre un error, se recupere y siga buscando errores. Por lo tanto el manejador de errores de un analizador sintáctico debe tener como objetivos:
Muchos errores de naturaleza sintáctica Recuperación: Al producirse un error el compilador debe ser capaz de informar del error y seguir compilando. (Ideal).
El manejo de errores de sintaxis es el más complicado desde el punto de vista de la creación de compiladores. Nos interesa que cuando el compilador encuentre un error, se recupere y siga buscando errores. Por lo tanto el manejador de errores de un analizador sintáctico debe tener como objetivos:
- Indicar los errores de forma clara y precisa. Aclarar el tipo de error y su localización.
- Recuperarse del error, para poder seguir examinando la entrada.
- No ralentizar significativamente la compilación.
Un buen compilador debe hacerse siempre teniendo también en mente los errores que se pueden producir; con ello se consigue:
- Simplificar la estructura del compilador.
- Mejorar la respuesta ante los errores.
Errores semánticos.
Un lenguaje con comprobación fuerte de tipos es capaz de garantizar que los programas se pueden ejecutar sin errores de tipo, por lo que los errores de tipo se detectarán siempre en tiempo de compilación.
Como mínimo, ante un error, un comprobador de tipos debe informar de la naturaleza y posición del error y recuperarse para continuar con la comprobación del resto del programa a analizar.
Veamos algunas de las operaciones a tener en cuenta en una comprobación de tipos:
Como mínimo, ante un error, un comprobador de tipos debe informar de la naturaleza y posición del error y recuperarse para continuar con la comprobación del resto del programa a analizar.
Veamos algunas de las operaciones a tener en cuenta en una comprobación de tipos:
- Conversión de tipos: A veces es necesario transformar el tipo de una expresión para utilizar correctamente un operador o para pasar de forma adecuada un parámetro a una función.
- Coerción: Es una conversión de tipos que realiza de forma implícita el propio compilador. Si es el programador el que realiza la conversión se tratará entonces de una conversión explícita.
- Sobrecarga de operadores: La sobrecarga se resuelve determinando el tipo de cada una de las expresiones intervinientes en la sobrecarga.
- Funciones polimórficas: Son aquellas que trabajan con argumentos cuyo tipo puede cambiaren distintas llamadas a la función.




